 |
|
 |
|
HaGenLex (HAgen GErmaN LEXicon) is a domain independent computational lexicon for German, which has been developed since 1996 at the Intelligent Information and Communication Systems (IICS) group of the FernUniversität in Hagen. HaGenLex entries carry detailed morphosyntactic and semantic information. The HaGenLex core lexicon currently (07/2005) comprises:
| 12986 | noun entries |
| 6911 | verb entries |
| 3278 | adjective entries |
| 579 | adverb entries |
The lexical material of HaGenLex has been manually compiled on the basis of frequency lists and publicly available dictionaries. For a more thorough introduction into HaGenLex see [1].
The semantic representation in HaGenLex is based on the MultiNet paradigm, which provides a hierarchy of 45 ontological sorts (object, action, location, property, etc) and a set of more than 100 semantic relations and functions. In addition, the 16 binary semantic features shown in Figure 1 are used.
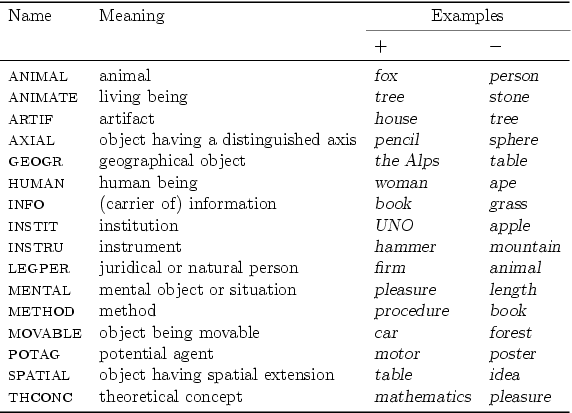
Figure 1: Binary semantic features
Each lexical concept is classified with respect to its ontological sort and its semantic features, which together determine the so-called semantic sort of the concept. Semantic valency is characterized by means of specific MultiNet relations, called cognitive roles (AGT, BENF, etc); selectional restrictions can be specified by ontological sorts and semantic features. The following data give a sketch of the semantic class and the case frame of the verb informieren (to inform):
action, MENTAL-
| AGT | OBJ | MCONT |
| LEGPER+ | LEGPER+ | |
| NP[nom] | NP[acc] | PP[über, acc] |
| obligatory | optional | optional |
The verb in question is assumed to denote a non-mental action with three participants, characterized respectively as agent (AGT), neutral object (OBJ), and mental content (MCONT), of which only the first one must be syntactically realized (in active voice). Moreover, the agent and the neutral object are required to be potential agents (POTAG+). (It should be mentioned that the feature MENTAL+ is restricted to purely mental processes as expressed by verbs like dream or think.)
Whereas the categorization of lexemes by semantic sorts and case frames
is fully integrated into the typed feature structure representation of
HaGenLex entries, additional semantic specifications can
be encoded as value of the feature NET, which allows one to include
arbitrary MultiNet expressions into lexical entries.
For example, the expression
(GOAL c n1) (MEXP n1 x2) (MCONT n1 x3) (SUBS n1 "wissen.1.1")
as part of the NET value of the lexeme informieren
(to inform)
roughly means that if x1 informs x2 about
x3 then x1 wants x2 to know x3.
(The symbol c stands for the concept of the given entry.)
This method thus allows one
to specify formal meaning
postulates within HaGenLex
[2].
HaGenLex entries are systematically linked to the lexical units of GermaNet [3]. This linking has been established and is maintained by the HaGenLex lexicographers. It is thus possible to project the sense relations of GermaNet onto HaGenLex, which is used, for instance, to check the semantic consistency of HaGenLex, or to employ the interlingual index of EuroWordNet.
The internal representation of HaGenLex entries makes use of a standard typed feature structure formalism. In addition to lists and disjunctions, also sets of atomic types are allowed as feature values. The implementation does not support path identities, which is no severe restriction because the HaGenLex feature architecture is designed for lexical information only and not for phrasal constraints.
The type hierarchy of HaGenLex has the form of a taxonomic tree. In particular, the immediate subtypes of any type are pairwise incompatible. Besides standard types like case, the HaGenLex type hierarchy also includes the ontological sorts and the lexically relevant semantic relations of MultiNet. In accordance with the typed feature approach, a feature of the HaGenLex feature architecture is appropriate only in structures of a certain type, and the value of a feature is restricted by the type the feature is appropriate to. The feature MORPH, for instance, is only appropriate in structures of type sign. Since a type inherits all features appropriate to its supertype, the feature MORPH is appropriate to the type word because word is a subtype of sign. A (non-redundant) list of the appropriate features and their respective values for a given type is known as the feature declaration of that type. Here is a list of five instructive examples of HaGenLex feature declarations - with minor simplifications:
|
|
||||||||||||||||||
|
|
|
||||||||||||||||||||||||||||||||||||
Since the feature structure representation of a lexical entry is of type word and word is a subtype of sign, the topmost feature level of such a structure is determined by the feature declarations of word and sign. The value of the feature SEMSEL is a structure of type semsel, whose topmost feature level is given by the declaration of semsel; feature structures of this type represent the semantics and the valency of a lexeme. Valency in turn is encoded by a list of structures of type select-element, each of which characterizes a complement by a set of semantic relations (REL), its syntactic obligatoriness (OBLIG), and its description by a structure of type sign (SEL). Structures of type sem, finally, represent the semantics of a lexical sign by its semantic sort (ENTITY), additional MultiNet expressions (NET), layer information (LAY), and molecularity type (MOLEC).
Since feature declarations are rather restricted in expressing lexical regularities, HaGenLex in addition makes use of the IBL (Inheritance-Based Lexicon) formalism [4], which allows one to specify more complex constraints and defaults by so-called classes. A class is a named collection of attribute-value constraints that describes a typically underspecified typed feature structure. The class verb, for instance, is defined as follows, where question marks indicate default values:
verb [A class can inherit from other classes at top level or at specific path locations. The class verb is nonlexical in the sense that it is used in several lexical classes or other nonlexical classes. A lexical class is the IBL representation of a lexical entry; as an IBL class, it inherits the information of its superclasses. The IBL representation of the HaGenLex entry for informieren (to inform) has the following form:
word
syn [
v-syn
perf-aux ?haben
sep-prefix ?""
v-type ?main
v-control ?nocontr]]
"informieren.1.1" [Resolving all classes of an entry leads to the expanded form of the entry (example: expanded entry of informieren).
verb
semsel [
v-nonment-action
sem net /(goal c n1) (mexp n1 x2) (mcont n1 x3) (subs n1 "wissen.1.1")/
select <
[
agt-select
sel semsel sem entity legper +]
[
ornt-select
oblig -
sel [
syn np-acc-syn
semsel sem entity legper +]]
[
mcont-select
oblig -
sel syn (ueber-acc-pp-syn zu-dat-pp-syn darueber-dass-syn darueber-wh-syn none-wh-syn)] >
compat-r {dur tlim}
example "(Der Minister) (informiert) (das Parlament) (über das Gesetz)."
entail "x1 informiert x2 über x3: x2 hat nach c Kenntnis von x3"]
g-id "1 2"
origin "DS 1997-11-10"
history "FB 2002-11-26: sem net, select, entail"]
The current implementation of HaGenLex is based on a representation conforming with the Scheme programming language, both for IBL and expanded entries. For expanded entries, there are also several XML representations available, which are automatically generated from the Scheme representation [5].
The creation and maintenance of HaGenLex entries is supported by the lexicographer's workbench LIA (Lexicon in Action), which provides powerful browsing and editing facilities. LIA has a two-level architecture (see Figure 2). Its front-end, which is implemented in Tcl/Tk, controls the GUI, administrates the interfaces to other tools, hides the internal representation, and sets up the communication with a back-end Scheme application that realizes the actual inferences triggered by user actions. The inference machine of LIA is based on the feature declarations and class definitions underlying HaGenLex. In addition, there are LIA specific lexical rules to speed up the editing process by default inferences.
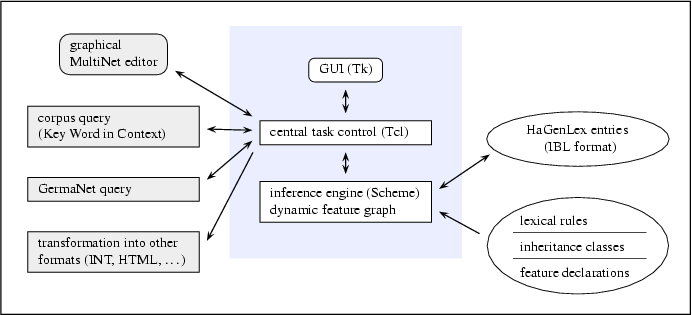
Figure 2: Overall architecture of LIA
LIA allows users to create and modify lexical entries without presupposing knowledge about their internal representation. To this end, LIA explicitly lists possible choices, say, of the semantic type of a certain noun or nominal complement, by using suggestive paraphrases. Moreover, LIA supports decisions of the lexicographer by asking for acceptability judgments; for instance, the information whether the complements of a verb are obligatory or optional is queried by presenting example sentences with one complement omitted. As to browsing, LIA allows users to create flexible subviews on the lexicon by freely selecting attribute-value combinations.
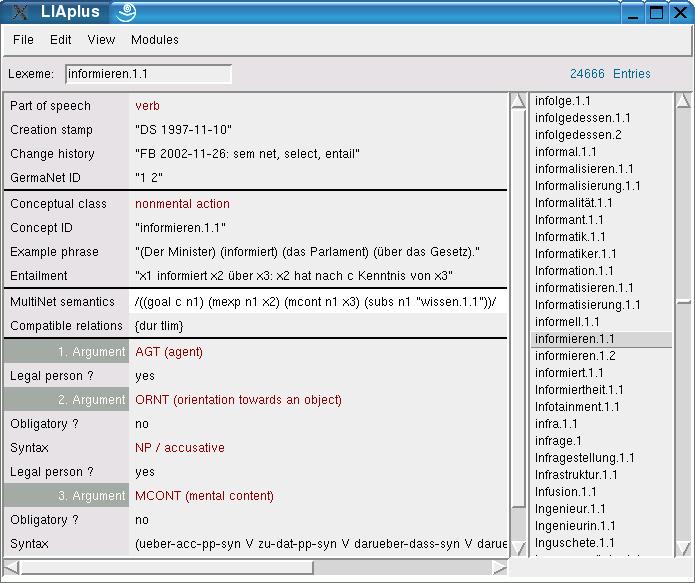
Figure 3: HaGenLex entry of the verb informieren
(to
inform) presented by LIA
LIA provides several interfaces to other software components of the HaGenLex-MultiNet system. For example, to facilitate editing lexical semantic specifications in form of MultiNet expressions, they can be loaded into a graphical MultiNet editor, which is part of the knowledge representation tool MWR (see Figure 4).
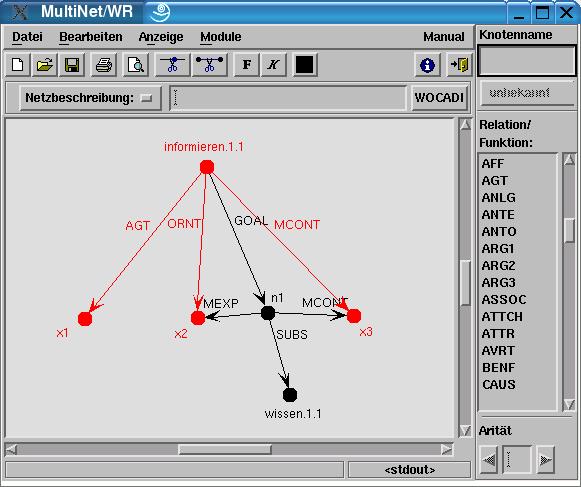
Figure 4: MultiNet semantics (relational part) for the HaGenLex entry
shown
in Figure
3
This interface can also be used to visualize the semantic parse of the entry's example sentence(s), which is generated by the syntactico-semantic analyzer WOCADI. The lexicographer can thus check whether or not an entry is correctly specified with respect to the example context.