 |
|
 |
|
If you want to test the parser, please send an e-mail to Dr. Sven Hartrumpf ([email protected])
The WOCADI parser (formerly: NatLink; WOCADI is an acronym for WOrd ClAss based DIsambiguating) is a computer program written in the Scheme programming language that transforms a German text into a formal semantic representation using the MultiNet (multilayered extended semantic networks) formalism. This representation can be used by a diversity of computer tools and applications like natural language interfaces, knowledge engineering systems, machine translation tools, question answering systems, etc. On the one hand, the WOCADI parser can provide a simple and intuitive front-end for users so that they can communicate with the computer in a natural language (in their mother tongue). No artificial command languages must be learned! On the other hand, the parser can make available the knowledge hidden in large text collections. The level of natural language understanding is much deeper than in search engines like Google or in traditional information retrieval systems.
This tour is a little demo of WOCADI. For demonstration purposes, you can select a German text among several texts with English translations. After your selection, the parser will generate intermediate and final results for the selected text, if your computer has Internet access. The reply can take some seconds since an illustrative image will be produced; the actual parsing typically needs less than 1 second. The parse results are presented in a newly generated web page. Explanations of the results can be found if you follow the links or if you read the rest of this page.
Feel free to experiment and report your findings and comments to Sven Hartrumpf.
The first intermediate result presented originates from two processing modules: a word and sentence tokenizer and a morpho-lexical analyzer which uses two computer lexica (a semantically deep lexicon called HaGenLex (HAgen GErmaN LEXicon) constantly extended by using the lexicon workbench LIA and a semantically flat lexicon). In addition, several dozens of name lexica are consulted.
The tokenizer decides where words and sentences start and end. It segments the user input into words and groups words into sentences. For humans, this is trivial; for computers, this is not always trivial. (Consider for example that a period might end a sentence or not depending on many context factors.)
The morpho-lexical analyzer determines the base form of words and the morphological information that the inflectional suffixes (or prefixes or infixes) add to the information originating from the base form. The analyzer returns for every word a large feature structure (containing around 20 to 80 feature values); for simplicity, only a small part of these feature structures is presented in this demo. A compound analysis module is applied to analyze the structure and semantics of compounds, which are quite popular in many German texts. An example of a nominal compound is Programmiersprache (programming language).
The meaning of the user input (a German text) is automatically determined by a parser which is based on word class functions (WCFs). The results of the parser are semantic networks from the MultiNet (multilayered extended semantic networks) formalism. This representation is formal so that computers can deal with them directly.
A semantic network contains two basic things: first, there are concepts like computer or peach. Second, there are relations between concepts (shown as directed edges), e.g. that a peach is a fruit or that Armstrong was an actively acting person (or AG(EN)T) when he stepped on the moon in July 1969. For more details on the MultiNet paradigm, please see the MultiNet tour. Semantic networks can be created and maintained using the workbench MWR.
The semantic representation is sent to applications in a textual format. The graphical format is only important if the WOCADI results are to be communicated to humans, like in this demo.
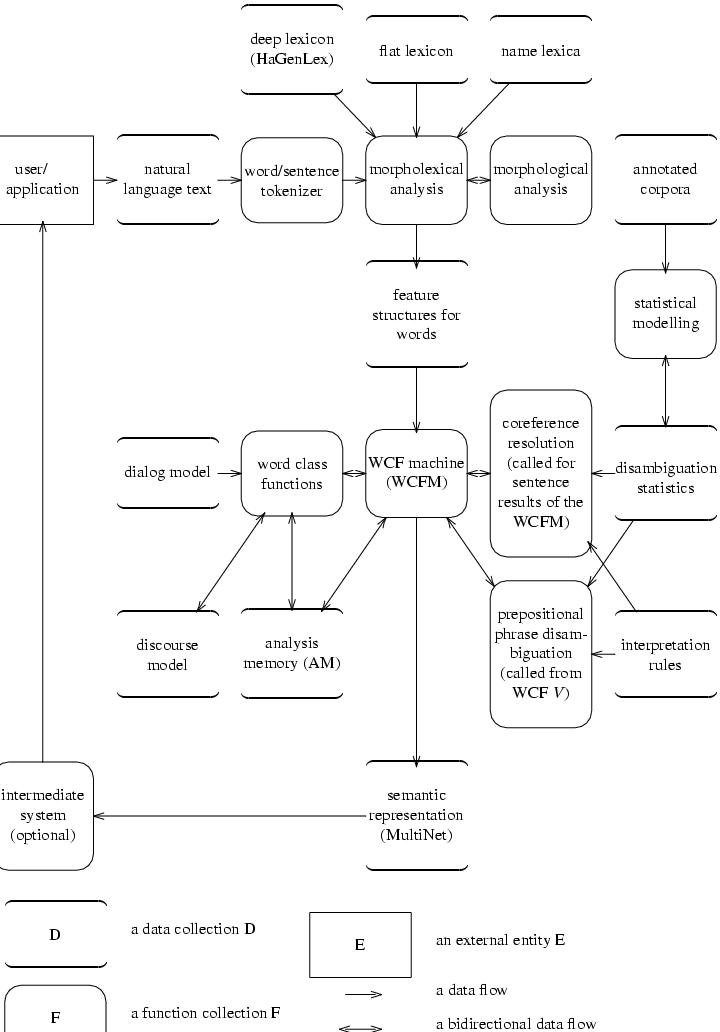
The following diagram shows the
structure of the WOCADI parser
and the main data flows. One possible embedding in an application
is indicated.
Here are some publications related to WOCADI:
A longer list can be found here.
Publications of IICS members.
IICS (Intelligent Information and Communication Systems), University of Hagen (FernUniversität in Hagen)