 |
|
 |
|
Falls Sie den Parser testen wollen, schicken Sie bitte eine Mail an Dr. Sven Hartrumpf ([email protected]).
Der WOCADI-Parser (früher: NatLink-Parser; WOCADI ist ein Akronym für WOrd ClAss based DIsambiguating) ist ein Computer-Programm, das in der Programmiersprache Scheme geschrieben ist. Es transformiert einen deutschen Text in eine formale semantische Repräsentation mittels des MultiNet-Formalismus (multilayered extended semantic networks). Diese Repräsentation kann von einer Palette von Computer-Werkzeugen und Anwendungen (z.B. natürlichsprachliche Schnittstellen (NLIs), Wissens-Engineering-Systeme, Werkzeugen zur maschinellen Übersetzung, Frage-Antwort-Systemen etc.) verwendet werden. Der WOCADI-Parser kann also einerseits einen einfachen und intuitiven Zugang bieten, so dass man mit dem Computer in einer natürlichen Sprache (der Muttersprache) kommunizieren können. Man muss daher keine künstlichen Kommando-Sprachen lernen! Auf der anderen Seite kann mit dem Parser das Wissen in großen Textbeständen erschlossen werden, und zwar weiter gehend als in Suchmaschinen wie Google oder in traditionellen Information-Retrieval-Systemen.
Diese Tour ist ein kleines Demo zum WOCADI-Parser. Zu Demonstrationszwecken kann man einen deutschen Text (mit englischer Übersetzung) aus einigen Beispieltexten auswählen. Nachdem man gewählt hat, erzeugt der Parser Zwischenergebnisse und Endergebnisse für den gewählten Text, falls Ihr Computer Internet-Zugang hat. Es kann ein paar Sekunden dauern, bis die Ergebnisse erscheinen, da ein illustratives Bild produziert wird; das eigentliche Parsen braucht normalerweise weniger als 1 Sekunde. Die Ergebnisse werden in einer neu generierten Web-Seite angezeigt. Erklärungen zu den Resultaten kann man finden, wenn man den Verweisen folgt oder wenn man den Rest dieser Seite liest.
Gern können Sie experimentieren und Ihre Erkenntnisse und Kommentare an Sven Hartrumpf senden.
Das erste dargestellte Zwischenergebnis stammt von zwei Verarbeitungs-Modulen: einem Wort- und Satzsegmentierer und einem morpho-lexikalischen Analysator, der zwei Computer-Lexika (ein semantisch reiches Lexicon namens HaGenLex (HAgen GErmaN LEXicon), das kontinuierlich mit der Lexikon-Werkbank LIA erweitert wird, und ein semantisch flaches Lexikon). Zusätzlich werden mehrere Dutzend Namen-Lexika konsultiert.
Der Segmentierer entscheidet, wo Wörter und Sätze anfangen und enden. Er zerlegt die Benutzer-Eingabe in Wörter und gruppiert Wörter zu Sätzen. Für Menschen ist dies trivial; für Computer ist dies nicht immer trivial. (Man bedenke zum Beispiel, dass ein Punkt einen Satz beendet oder nicht beendet in Abhängigkeit von vielen Kontext-Faktoren.)
Der morpho-lexikalische Analysator bestimmt die Grundform der eingegebenen Wörter und die zugehörigen morphologischen Informationen, welche die Flektions-Suffixe (oder Flektions-Präfixe oder Flektions-Infixe) zu den Informationen der Grundform hinzufügen. Der Analysator liefert zu jedem Wort eine große Merkmal-Struktur (mit ungefähr 20 bis 80 Merkmal-Werten); der Einfachheit halber wird nur ein kleiner Ausschnitt aus diesen Strukturen im Demo angezeigt. Ein Komposita-Modul wird eingesetzt, um die Struktur und Bedeutung von Komposita zu analysieren. Komposita wie Komposita-Modul und Programmiersprache sind in vielen deutschen Texten sehr beliebt.
Die Bedeutung der Benutzer-Eingabe (eines deutschen Textes) wird automatisch durch den eigentlichen Parser bestimmt, der auf Wortklassen-Funktionen (WCFs) beruht. Die Parser-Ergebnisse sind semantische Netzwerke aus dem Paradigma des MultiNet-Formalismus (multilayered extended semantic networks). Diese Repräsentation ist formal, so dass Computer direkt damit arbeiten können.
Ein semantische Netzwerk enthält zwei grundlegende Dinge: erstens gibt es Konzepte wie z.B. Computer oder Pfirsich. Zweitens gibt es Relationen (gezeichnet als gerichtete Kanten) zwischen Konzepten, z.B. dass ein Pfirsich eine Frucht ist oder dass Armstrong eine aktiv handelnde Person (oder AG(EN)T) war, als er den Mond im Juli 1969 betrat. Um mehr Details über das MultiNet-Paradigma zu erfahren, kann man die MultiNet-Tour zu Rate ziehen. Semantische Netzwerke kann man mit der MWR-Werkbank erzeugen und pflegen.
Die semantische Repräsentation wird an Anwendungen in einem textuellen Format geschickt. Das grafische Format ist nur dann wichtig, wenn die WOCADI-Ergebnisse für Menschen aufbereitet werden sollen, wie z.B. in diesem Demo.
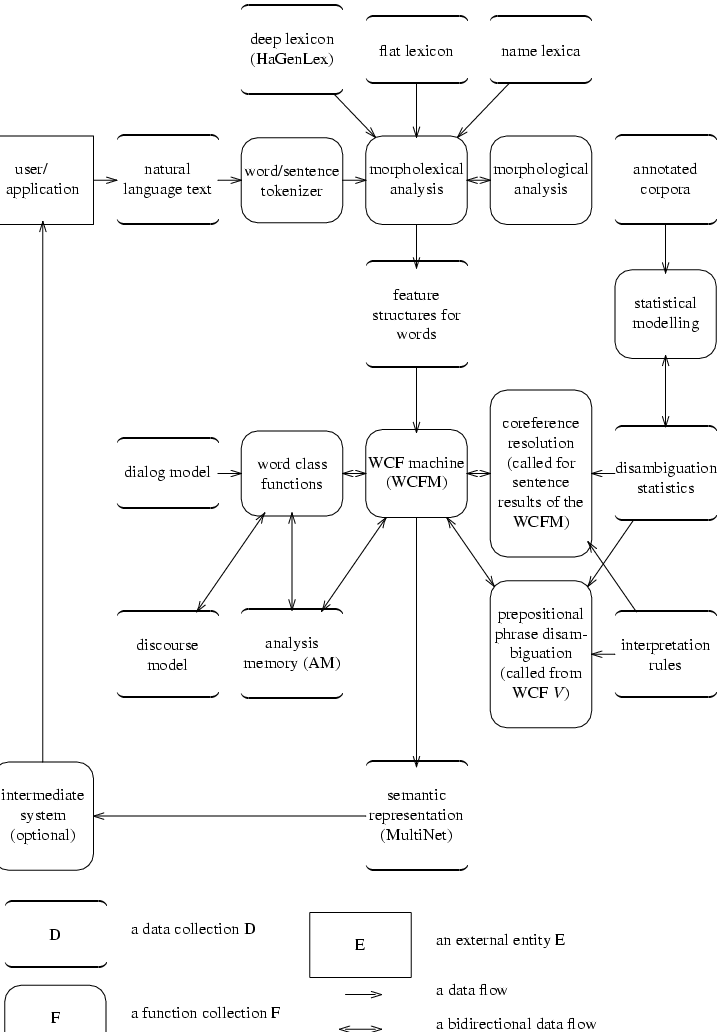
Das folgende Diagramm zeigt die
Struktur des WOCADI-Parsers und
die Hauptdatenströme. Eine mögliche Einbettung in
eine
Anwendung ist angedeutet.
Hier sind einige Publikationen über WOCADI:
Eine längere Liste
kann man hier
finden.
Publikationen
von
IICS-Mitarbeitern.
IICS (Intelligente Informations- und Kommunikationssysteme), FernUniversität in Hagen